 Background
Background
Credit card fraud remains one of the fastest-evolving financial crimes, costing global institutions billions of dollars annually. Traditional rule-based systems often struggle to keep up with the sophistication of modern fraud schemes.
At DatalytIQs Academy, we explored how Logistic Regression, a classical statistical model, can play a critical role in modern fraud analytics when paired with balanced datasets and cost-sensitive learning.
Model & Method
We trained a Logistic Regression (LogReg) classifier on a highly imbalanced dataset of 284,807 credit card transactions, where fraudulent cases represented less than 0.2%.
To address this imbalance:
-
We used class weighting to penalize missed frauds (False Negatives) more heavily than false alarms (False Positives).
-
The model output was evaluated using Precision–Recall (PR) curves and cost-sensitive thresholds.
Key Results
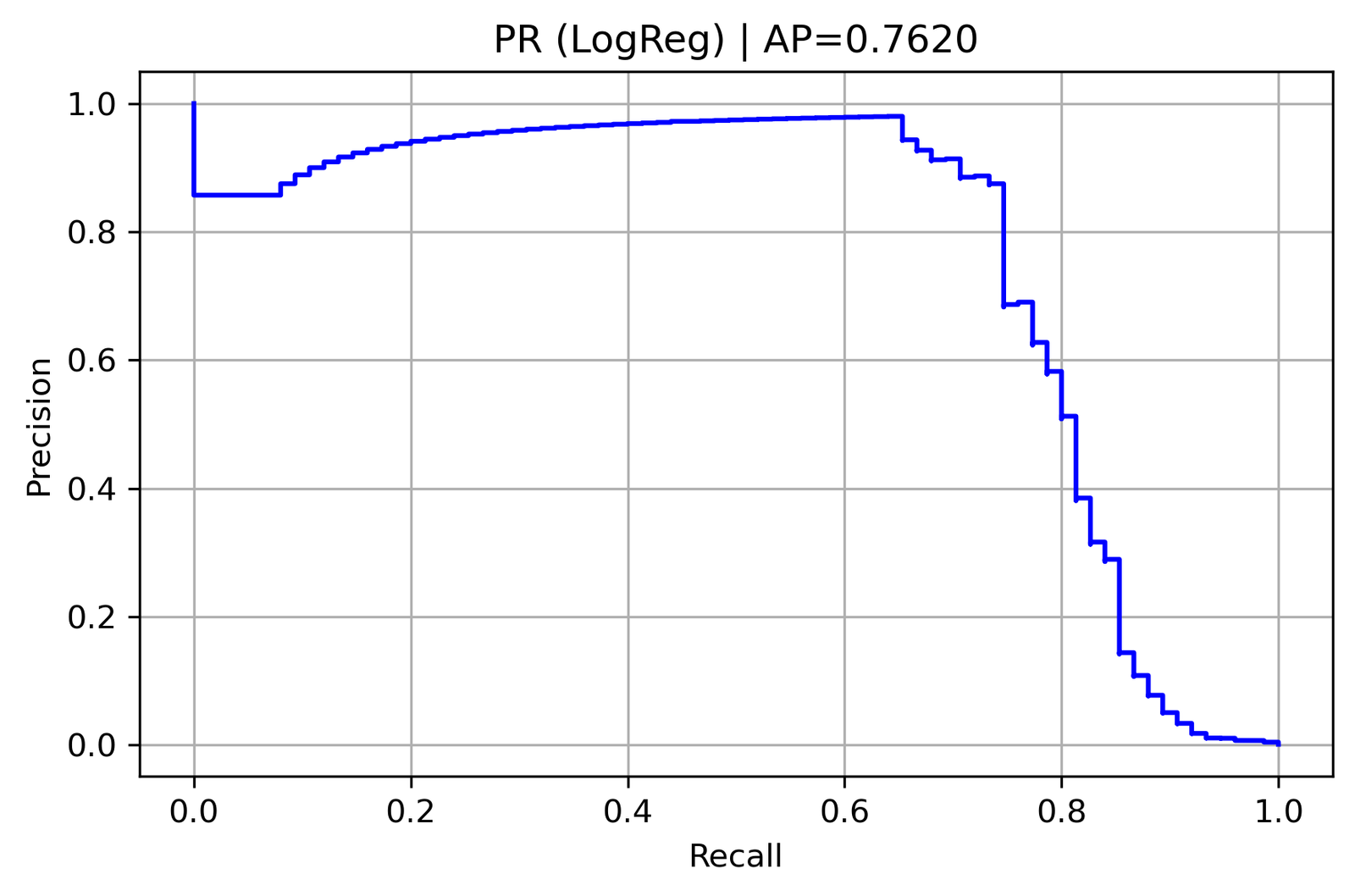
Precision–Recall (LogReg Balanced)
Average Precision (AP) = 0.7620
ROC-AUC = 0.98627
At the optimal cost-based threshold (≈ 0.98):
-
False Positives (FP): 58 legitimate transactions flagged
-
False Negatives (FN): 14 fraudulent transactions missed
-
Total Cost: 338.0 (with )
Classification Metrics:
| Metric | Class 0 (Non-Fraud) | Class 1 (Fraud) | Interpretation |
|---|---|---|---|
| Precision | 0.9998 | 0.5126 | Fraud alerts are correct half the time—acceptable in real-time filtering. |
| Recall | 0.9990 | 0.8133 | 81% of actual frauds detected—strong detection capacity. |
| F1-Score | 0.9994 | 0.6289 | Good balance between fraud capture and false alarms. |
| Accuracy | 0.9987 | High but secondary to recall in fraud tasks. |
Interpretation
The Logistic Regression model achieved robust performance despite the dataset’s imbalance.
-
Its PR curve remained high and stable up to recall ≈ 0.7, showing strong discrimination between genuine and fraudulent transactions.
-
The cost-optimized threshold (0.98) effectively minimizes financial loss by prioritizing recall (catching more fraud) over convenience.
This reflects an important risk management principle:
“In fraud detection, a small inconvenience is better than a large financial loss.”
Policy Implications
Financial regulators and banking institutions can draw several lessons:
-
Integrate cost-sensitive thresholds into fraud systems—missed frauds (FN) should weigh more heavily than false alerts (FP).
-
Combine algorithmic detection with human oversight—transactions with probabilities between 0.9 and 0.99 can be flagged for manual review.
-
Periodic model retraining ensures adaptability to new fraud behaviors.
-
Cross-agency data sharing (with privacy safeguards) can improve fraud trend monitoring.
Academic Insight
This experiment highlights how even interpretable models such as Logistic Regression, when tuned with data balancing and threshold optimization, can achieve near-state-of-the-art fraud detection performance.
It bridges mathematics, economics, and finance, turning data into actionable intelligence.
Author: Collins Odhiambo Owino
Institution: DatalytIQs Academy – School of Mathematics, Economics & Finance
Data Source: Kaggle Credit Card Fraud Dataset (European card transactions, anonymized features V1–V28)
Analysis Tool: Jupyter Notebook | Python (scikit-learn, matplotlib, pandas)
🙏 Acknowledgements
Special thanks to:
-
The Kaggle community for maintaining the open Credit Card Fraud dataset.
-
DatalytIQs Academy research team for model tuning and interpretation.
-
Learners and data scientists whose contributions keep AI in finance transparent and responsible.
Note
Machine learning doesn’t eliminate fraud; it elevates vigilance.
Each model we build is a step toward a safer financial ecosystem, where algorithms protect both trust and money.
Leave a Reply
You must be logged in to post a comment.