From Linear to Nonlinear Thinking
After exploring feature distributions, class differences, and a logistic regression baseline, it was time to test how a more flexible model performs.
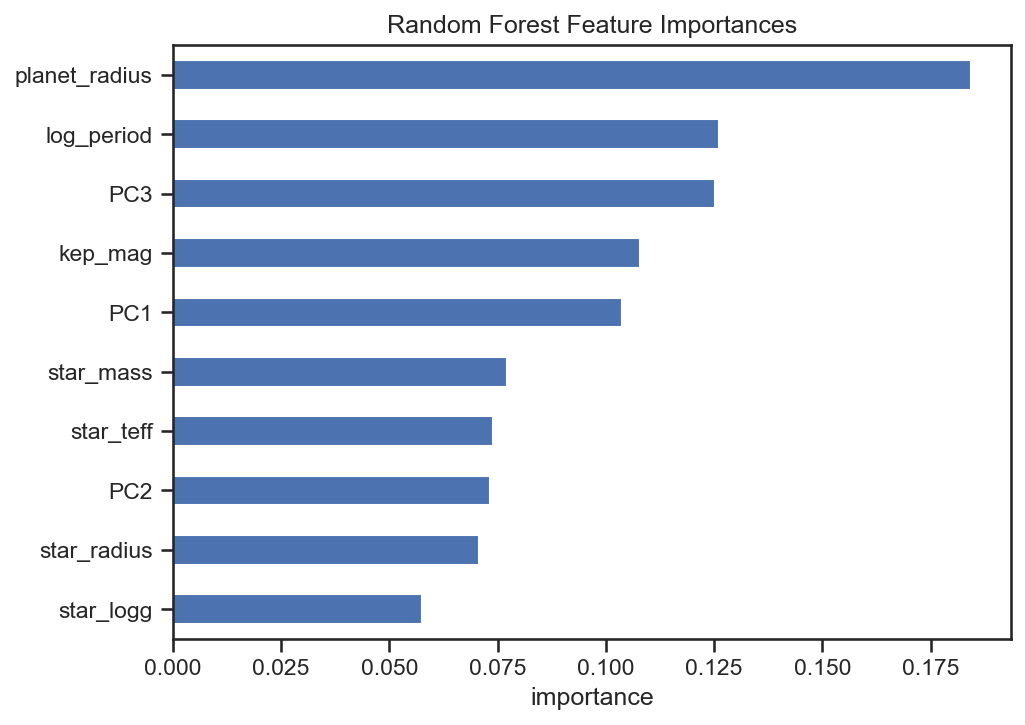
The Random Forest Classifier, a non-linear ensemble of decision trees, was trained on the same Kepler dataset to identify which features most influence planetary classification.
The figure below shows each feature’s relative importance, how much it contributes to accurate classification.

Reading the Forest: Which Features Matter Most
| Rank | Feature | Interpretation |
|---|---|---|
| 1 | planet_radius | By far the strongest predictor — size determines classification. Larger planets are far easier to confirm, while smaller ones blend into stellar noise. |
| 2 | log_period | Orbital period ranks second — short-period planets transit frequently, boosting detection confidence. |
| 3 | PC3 | A key principal component summarizing subtle light-curve variations that linear models struggle to capture. |
| 4–5 | kep_mag, PC1 | Stellar brightness and the first PCA axis both encode the photometric signal quality. |
| 6–8 | star_mass, star_teff, PC2 | These shape the environment around the planet; heavier or hotter stars influence signal intensity. |
| 9–11 | star_radius, star_logg | While physically meaningful, their marginal contribution suggests overlapping information with other stellar parameters. |
Insight: Beyond the Numbers
The Random Forest model shifts our perspective:
-
Nonlinear models reveal subtle, multi-feature relationships invisible to simple regressions.
-
The dominance of planet_radius confirms that the most visually measurable traits drive most detection confidence.
-
Yet, PC features (PC1–PC3) matter — proving that data-derived signals, not just physical attributes, are critical in modern astrophysics.
This means AI is learning astrophysics indirectly — through feature transformations that mimic what astronomers call signal decomposition.
Policy and Scientific Implications
| Focus | Recommendation | Strategic Outcome |
|---|---|---|
| 1. Mission Planning | Allocate observation time to faint or long-period systems. | Reduces discovery bias toward short, bright systems. |
| 2. Data Governance | Mandate open feature-engineering standards in exoplanet datasets. | Ensures transparency and reproducibility in ML-driven science. |
| 3. Research Collaboration | Combine physical features (radius, mass) with signal-derived PCA features from multi-mission data (Kepler, TESS, JWST). | Yields deeper, model-agnostic planetary classification. |
| 4. Education | Incorporate AI explainability into astrophysics curricula. | Builds a generation of scientists who understand both stars and statistics. |
Technical Reflection
-
Why Random Forest?
Unlike logistic regression, which assumes linear separability, Random Forest handles complex boundaries between classes.
It also ranks feature relevance, making it a transparent bridge between explainable AI and physical science. -
Model Observation:
The fact that PCA-derived features rank nearly as high as physical features suggests that data transformations carry astrophysical meaning — an exciting direction for data-driven astronomy.
Acknowledgements
-
Dataset: NASA Kepler Exoplanet Archive (via Kaggle).
-
Analysis & Modeling: Collins Odhiambo Owino — Lead Data Scientist, DatalytIQs Academy.
-
Tools: Python (
scikit-learn,matplotlib,seaborn,pandas). -
Institutional Credit: DatalytIQs Academy — advancing knowledge through data science, astronomy, and open policy analytics.
Closing Thought
“In the forest of data, patterns are the stars —
and learning algorithms are our telescopes.”
With the Random Forest’s insight, we close this analytical journey — from distributions and sky maps to predictive modeling and policy vision.
Each dataset, like each star, holds the potential to teach us not just what is out there, but how to see it better.
Leave a Reply
You must be logged in to post a comment.