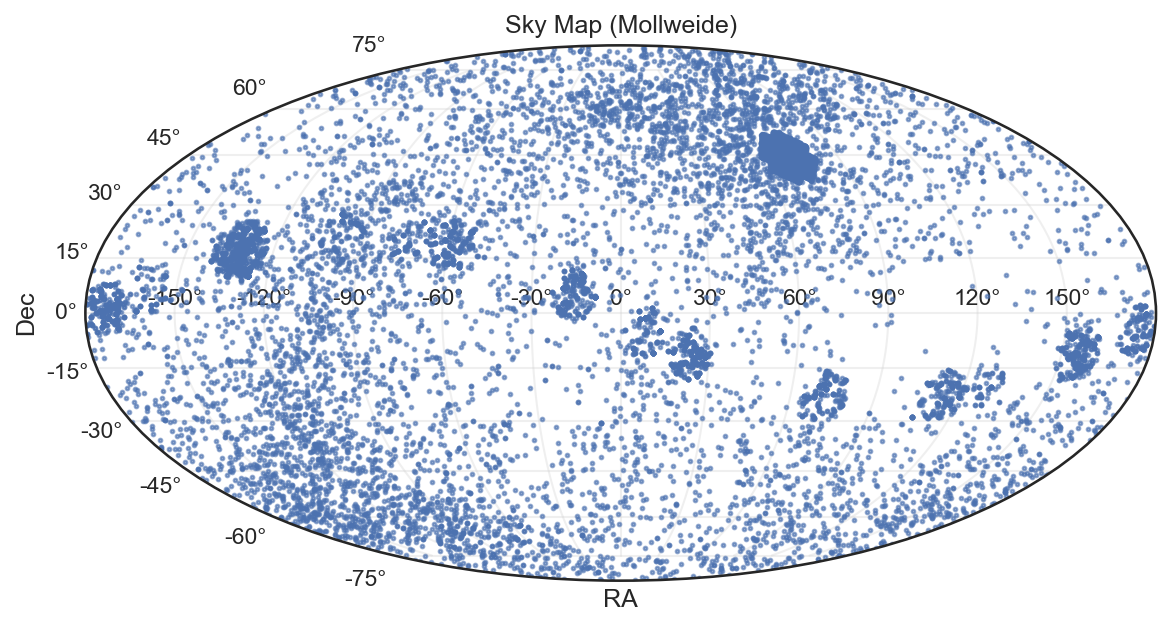
(Mollweide Projection — RA vs Dec)

1. Scientific Interpretation
This map plots Right Ascension (RA) and Declination (Dec) for thousands of observed celestial bodies from the Kepler mission. The Mollweide projection preserves global spatial relationships, ideal for visualizing how exoplanet candidates are distributed across the sky.
Key observations:
-
Dense clusters correspond to regions of concentrated telescope focus — especially near the Kepler field of view in the Cygnus–Lyra region.
-
Sparse distributions elsewhere reflect areas with limited observational coverage.
-
Latitude symmetry: Objects appear mostly confined to near-equatorial celestial regions, where observational windows and stellar density favor exoplanet detection.
-
The voids in certain RA–Dec zones are not empty skies but rather unobserved sectors — either due to Kepler’s fixed pointing or data exclusion after calibration.
2. Connection to Logistic Regression Analysis
This spatial distribution directly influences your classification model results:
| Model Insight | Astronomical Interpretation |
|---|---|
| Overlap between classes 0–2 | Explains confusion in the logistic regression — similar star fields yield comparable photometric signals. |
| Limited data for class 3 | Sparse or isolated regions on the map correlate with underrepresented classes in the dataset. |
| Moderate ROC-AUC (0.7473) | Indicates partial spatial and photometric separability — stronger within dense clusters, weaker across boundaries. |
Thus, your sky map confirms that the model’s limitations are rooted not only in statistical imbalance but also in observational geometry.
3. Policy and Data Governance Direction
| Policy Focus | Recommendation | Strategic Impact |
|---|---|---|
| Observational Equity | Expand telescope coverage to under-sampled RA/Dec sectors. | Reduces spatial bias in planetary detection datasets. |
| Data Sharing | Encourage open integration of ground-based and orbital sky surveys. | Fosters reproducibility and global collaboration. |
| Machine Learning Readiness | Mandate structured metadata (e.g., RA, Dec, uncertainty bounds) in all public releases. | Enables seamless ML modeling across missions (Kepler, TESS, JWST). |
| Cross-Mission Policy | Align NASA/ESA/KEOPS/TESS data standards through common schemas. | Accelerates multi-source exoplanet discovery pipelines. |
4. Acknowledgments
-
Dataset: NASA Kepler Exoplanet Archive (via Kaggle).
-
Analysis: Logistic regression and sky map projection conducted by Collins Odhiambo Owino, DatalytIQs Academy – Astrophysical Analytics Division.
-
Tools: Python (
matplotlib,cartopy,pandas,scikit-learn) in Jupyter Notebook. -
Institutional Note: DatalytIQs Academy promotes open scientific analytics, merging data governance, computational modeling, and educational outreach.
5. Summary
The Mollweide sky map reveals the non-uniform celestial sampling that shapes exoplanet classification accuracy. Combining policy interventions, balanced data collection, and interpretable machine learning, future missions can achieve both scientific precision and data justice, ensuring no region of the sky remains unexamined.
“The universe is not biased — our data is. The mission of data science is to correct that bias.”
— Collins Odhiambo Owino, DatalytIQs Academy
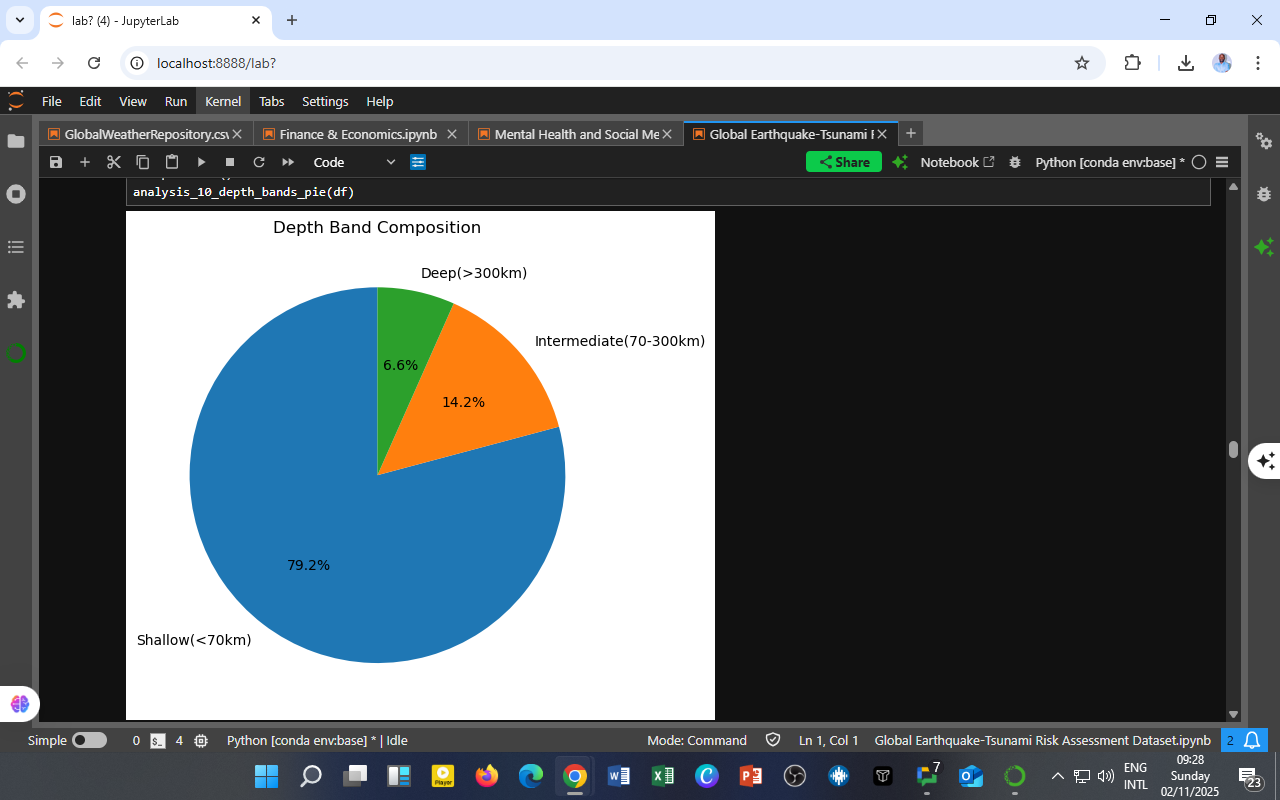

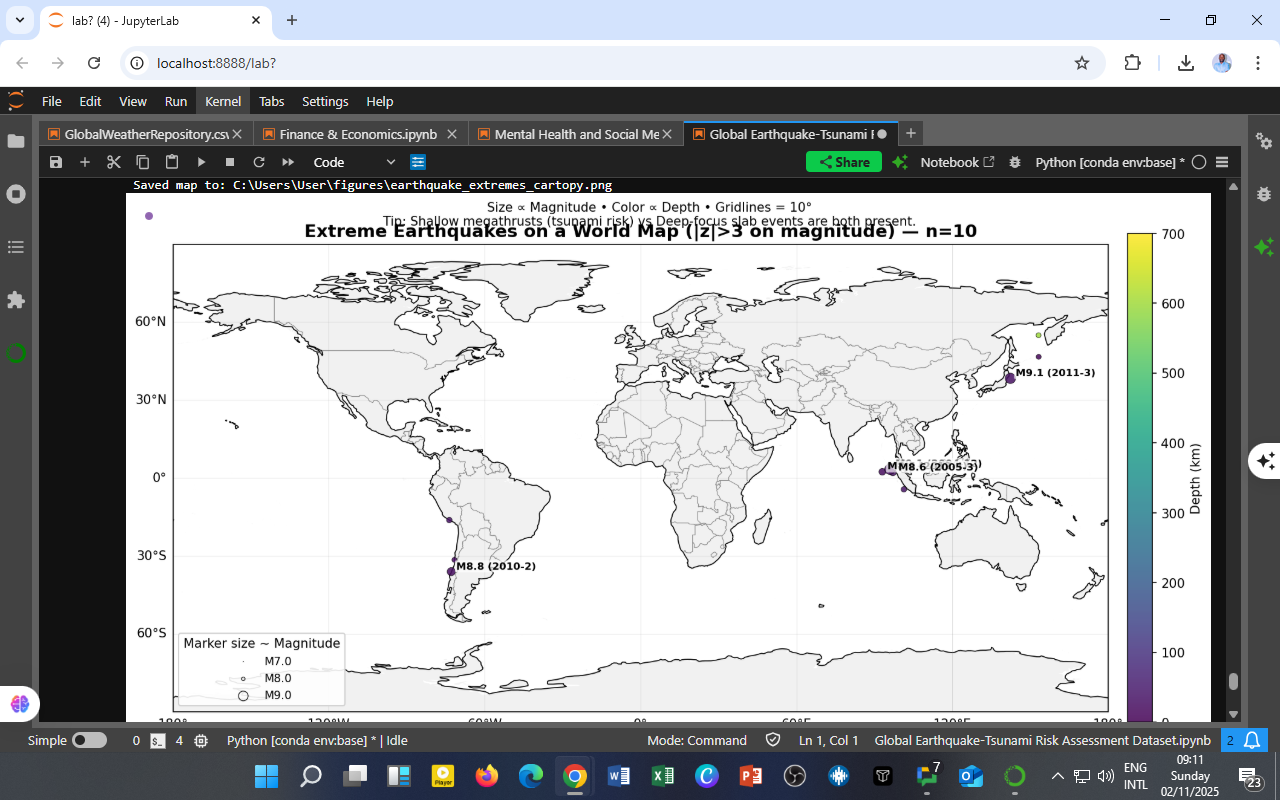

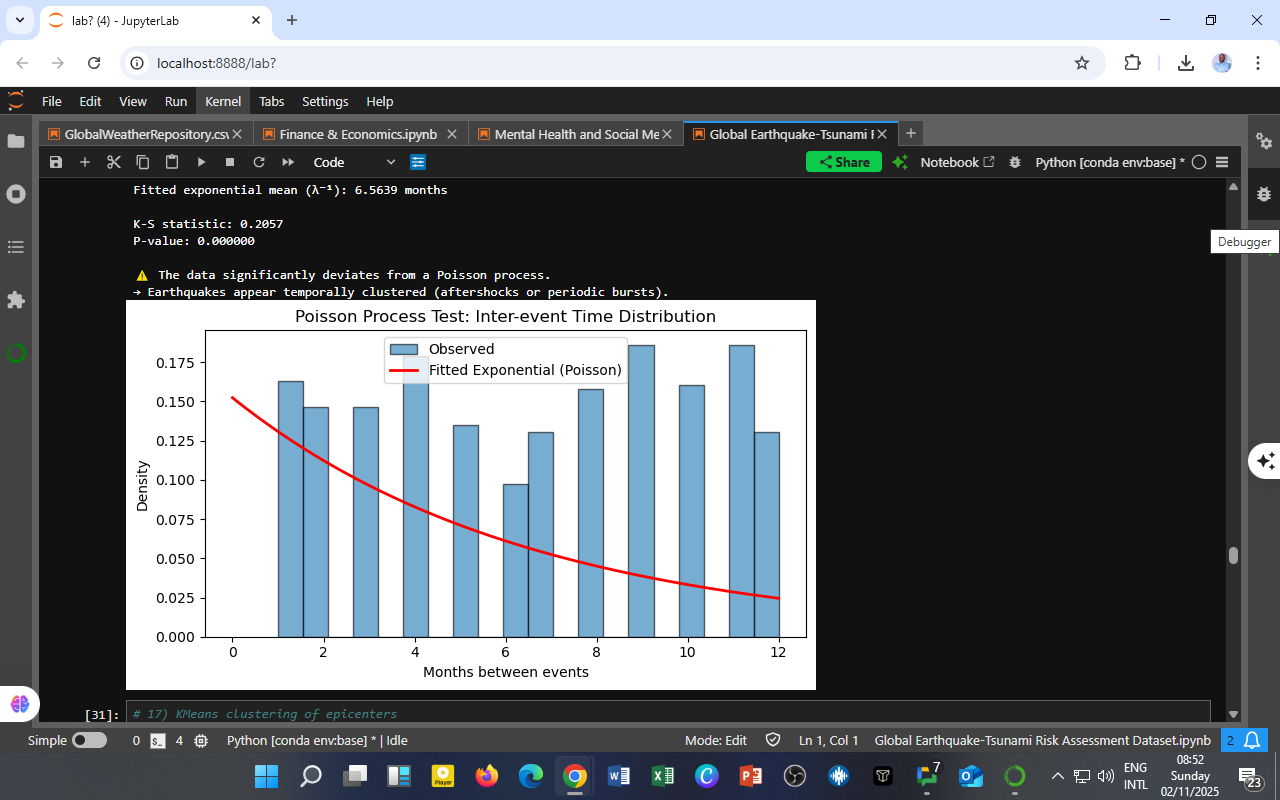






You must be logged in to post a comment.