Learning outcomes are rarely random; they emerge from a combination of habits, consistency, and personal effort.
To understand what shapes student performance, we analyzed the Kaggle — student_exam_scores.csv dataset and used Spearman correlation to explore how variables such as hours studied, sleep hours, attendance percentage, and previous scores relate to final exam results.
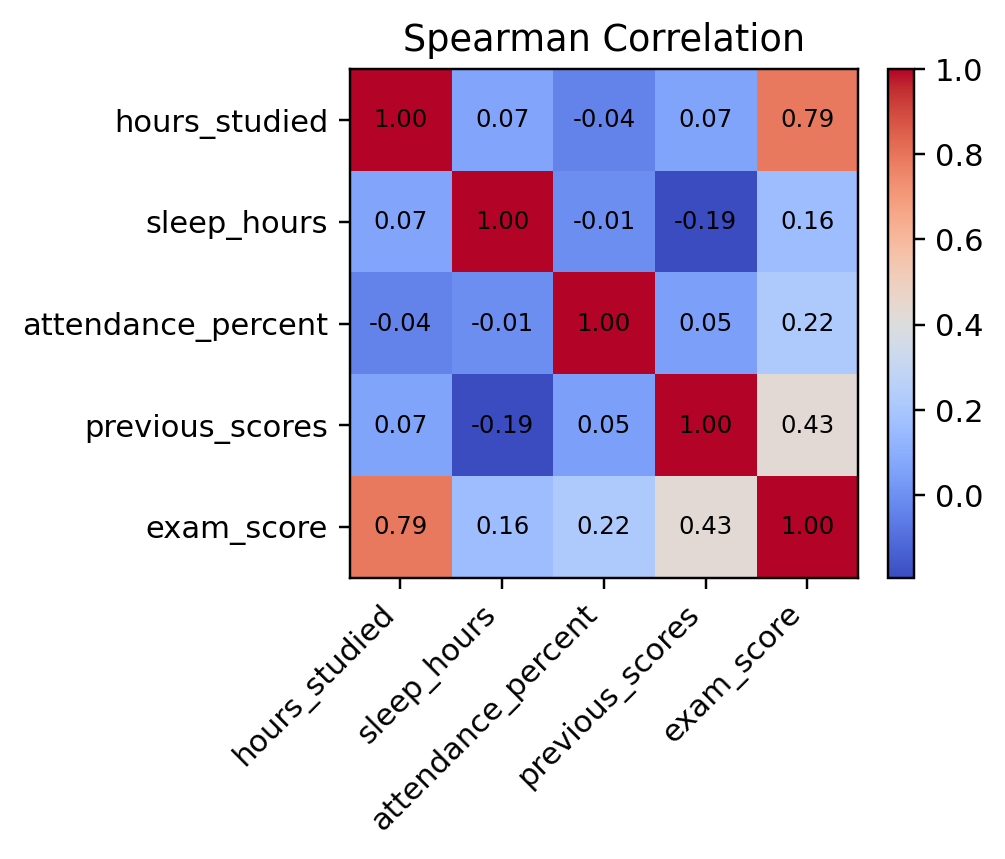
Understanding the Correlation Map

The heatmap displays the strength and direction of associations between key variables.
Spearman correlation is particularly suited for this analysis because it measures monotonic relationships, how one variable moves relative to another, not just linearly.
The scale ranges from -1 (perfect negative correlation) to +1 (perfect positive correlation).
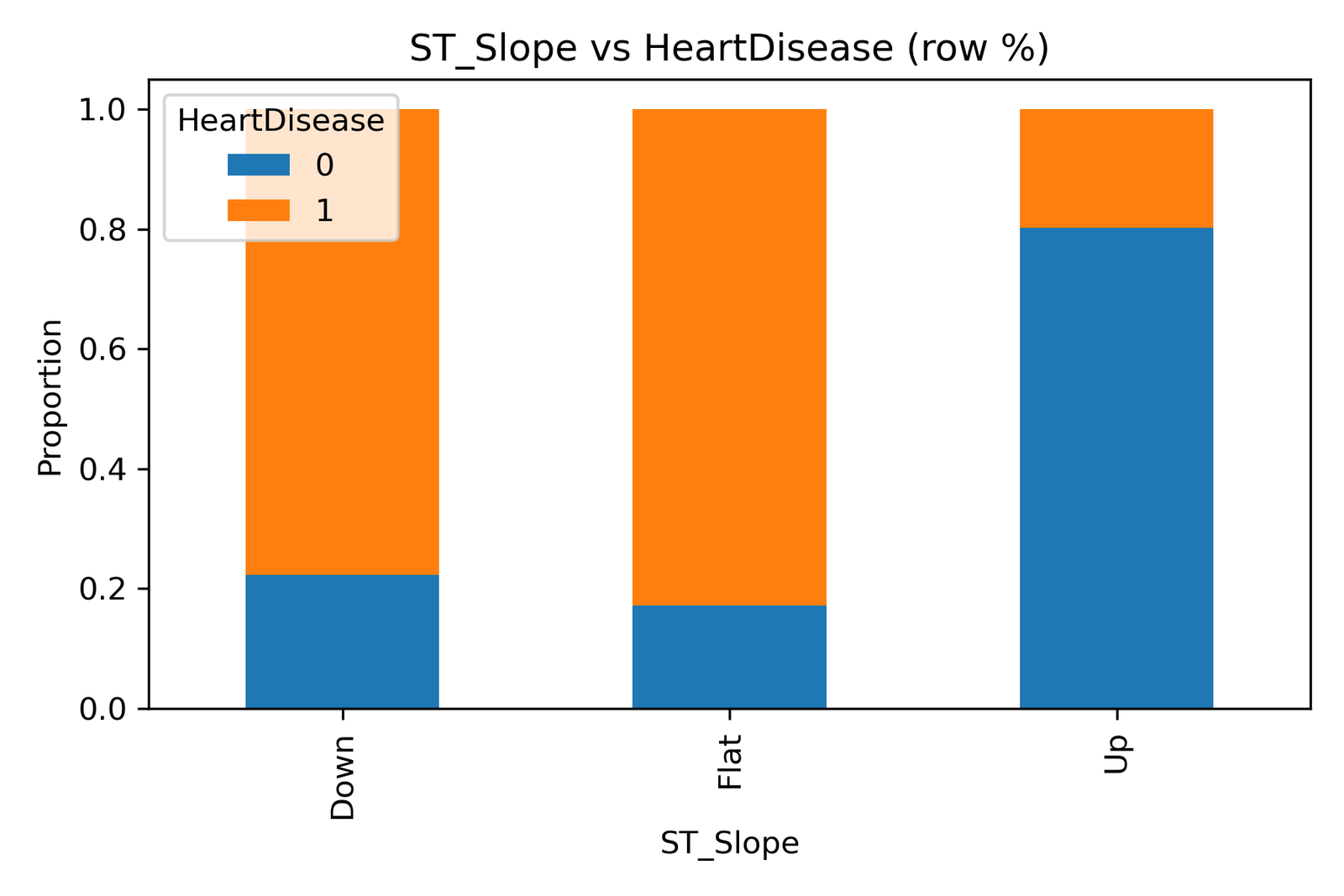
Key Insights from the Heatmap
-
Hours Studied vs Exam Score (ρ = 0.79):
This strong positive correlation shows that increased study time is directly associated with better exam performance. Students who dedicate more hours to study tend to achieve higher scores, reinforcing the timeless principle: effort drives results. -
Previous Scores vs Exam Score (ρ = 0.43):
Moderate correlation indicates that students who performed well before are likely to maintain consistency. It highlights the importance of academic continuity, and learning builds on past achievements. -
Attendance vs Exam Score (ρ = 0.22):
A weak but positive relationship suggests that attending classes contributes modestly to exam performance, possibly due to differences in how students utilize classroom time or self-study methods. -
Sleep Hours (ρ = 0.16 with Exam Score):
Surprisingly low correlation implies that while sleep is crucial for health, its direct measurable effect on performance may vary across individuals. -
Other Interactions:
-
A slight negative link between previous scores and sleep hours (-0.19) could indicate that high-performing students may be studying longer, sometimes at the cost of sleep.
-
Attendance shows minimal correlation with other variables, implying it’s an independent behavioral factor.
-
Educational Implications
| Factor | Strength of Influence on Exam Scores | Takeaway |
|---|---|---|
| Hours Studied | Strong (ρ = 0.79) | Reinforce study planning and consistency |
| Previous Scores | Moderate (ρ = 0.43) | Track progress over time to maintain momentum |
| Attendance | Weak (ρ = 0.22) | Attendance alone is not enough — engagement matters |
| Sleep Hours | Weak (ρ = 0.16) | Encourage balanced routines for focus and memory |
Strategic Takeaways
These correlations highlight that academic performance is multi-dimensional, shaped by persistence, preparation, and prior learning.
For educators and students alike:
-
Data-driven study planning can help identify which habits contribute most to outcomes.
-
Schools can integrate these analytics into performance dashboards to guide personalized tutoring and motivation systems.
-
Students can self-assess their habits and make informed improvements toward balanced productivity.
Acknowledgment
Data Source: Kaggle — student_exam_scores.csv
Analysis and Visualization: Education Analytics Unit, DatalytIQs Academy (2025)
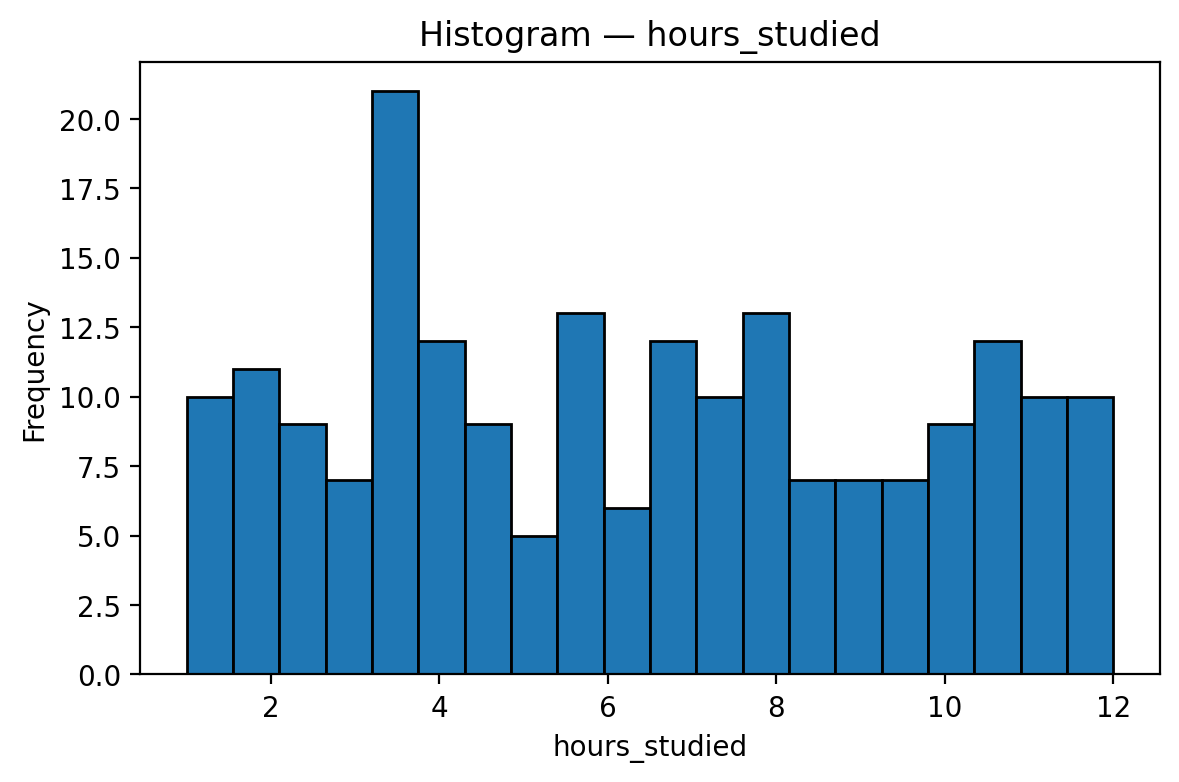
 The histogram presents the frequency of students according to their hours studied per day, ranging roughly from 1 to 12 hours.
The histogram presents the frequency of students according to their hours studied per day, ranging roughly from 1 to 12 hours.








You must be logged in to post a comment.